[메타코드] n8n 스터디 후기_2주차 : 뉴스 공지 자동화
일부 이미지가 생략되어 있습니다. 더 자세한 내용은 하단 [학습 정리 자료]의 네이버 블로그 원본 링크를 참고해주세요.
[2주차에 들어가며]
1주차에는 특정 기사 링크를 전달해 해당 기사에 대해서만 메일을 보냈다.
즉 1회성이였다면 2주차에서는 RSS를 통하면 자동화를 할 수 있다.
실제 python에서 자동화 크롤링을 할때에도 RSS가 있는 사이트는 RSS를 이용하면 코드 간편하게 크롤링을 할 수 있었다. 처음 크롤링을 배울때는 selenium, beautifulsoop을 사용하고 실제 페이지 가서 크롤링하고 싶은 css_selector 인자를 가져와서 정규화하고 그랬는데 기술이 발전함에따라서 n8n하나로 가능해진게 정말 신기하다.
n8n으로 했을때는 내가 python으로 했던것과 어떤 것이 많이 다르고 이때 공부했던 지식이 어느정도 도움이 되었는지에 대해서도 생각하면서 이번 2주차 n8n 공부를 하였다.
[RSS란?]
RSS: Rich Site Summary 또는 Really Simple Syndication의 약자
즉, 특정 사이트에서 새로운 컨텐츠가 올라왔을때 ‘빠르고’ ‘효과적‘으로 ‘웹사이트를 방문하지 않고’ RSS를 통해서 콘텐츠를 쉽게 이용할 수 있다.
예전에 크롤링 하면서 느꼈던 것은 RSS 하나에 해당 사이트의 모든 컨텐츠에 대한 정보가 들어가있어서 내가 원하는 카테고리를 선택하여서 가져올 수도 있었다. 사실 RSS만 있으면 코드가 엄청 단순해졌다.
나무위키에 나와있는 말이 공감이 되었는데 그대로 인용하겠다.
“쉽게 생각하면, 여러 언론사 사이트를 모두 방문할 필요 없이 다양한 기사를 네이버뉴스 한 곳에서 볼 수 있는 것과 같다고 보면 된다.” 이 말이 젤 최적의 말인 것같다.
예전에는 RSS가 있는 뉴스들을 n분마다 업데이트를 파악하여서 새로운 기사를 가져오고 openai api를 통해서 프롬프트로 정제한 후에 카페에 올리는 자동화를 만든적이 있었다.
Github 뉴스 RSS 크롤링 (참고용으로 로컬에서 과거 실제 만들었던 python 파일을 올리겠다.)
[과제]
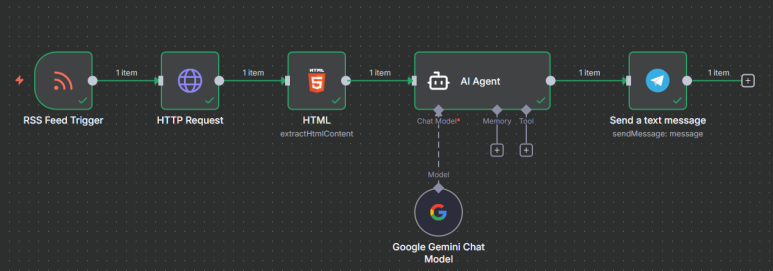
1-1. RSS 트리거 만들기
다시 1주차를 상기 시킨다! 처음은 뭘로 시작한다?
“Trigger!!!!!!” -> 항상 n8n의 시작은 Trigger
이번에는 RSS 를 이용하므로 RSS를 가져오는 Trigger을 만들자.
1-2. RSS 트리거 세팅 및 설명
1) Mode: ‘Every hour’은 매 시간마다 ` Minute: ‘0’은 0분
즉, 매 시간 0분마다 = 정각마다 Trigger을 실행한다. 라는 뜻이다. 만약, Minute에 11이 들어가면 매 시간 11분마다 즉, 00:11, 01:11, 02:11, …, 23:11 까지 계속 반복하라는 뜻이다.
Mode마다 변수가 다른데 이런식으로 해석을 하면 된다.
2) Feed URL: 내가 Feed 하고싶은 URL 입력하면 됨
1-3. RSS 트리거 실행 결과
Q. 이렇게 쉽게 가져오면 바로 AI Agent를 사용할 수 있는 것이 아닌가요?
A. 위 이미지의 주황색 동그라미 친 부분을 보면 “개발을…” 으로 모든 전문이 다 보이는 것이 아니고 중간에 끊겨서 나온다. 따라서, 즉시 AI Agent를 활용해서 메일을 보낸다던가, 요약을 한다던가 하는 행동을 할 수 없음.
Q. 그럼 어떻게 하나요?
A. 밑줄 친 부분을 보면 “link”를 가져올 수 있으니 1주차처럼 이 링크를 파싱을해서 기사 본문을 가져오면 됨!
2-1. HTTP Request 노드 생성 및 개념 설명
이제는 노드 추가하는 방법은 생략하겠다. 적응이 되었기 때문에!
(Trigger node의 우측에 조그만한 + 버튼을 누른 후 -> 우측에 뜨는 검색창에서 필요한 것을 검색하여서 추가하면됨)
2-2. HTTP Request 노드 설정
1) Expression으로 해야지 우리가 직접 데이터를 가져와서 사용할 수 있다. 이건 다른 노드에서 할때도 마찬가지(ex. ai agent에 프롬프트 입력할때)
2) 우리는 “link”를 파싱해서 해당 링크 정보를 가져와야하므로 “link”를 URL 쪽으로 드래그
3) 나는 이 User-Agent를 예전 python에서 크롤링할때 Header 값을 위장해서 들어간다고 들었었다.
그래서 내 기억이 맞는지 개발자 도구에서 Network를 들어가니 Headers에 User-Agent가 있어서 나는 Header에 User-agent 값을 넣었다.
{
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
이와 같이 실제 사람이 접속 한 것처럼 해줘야지 들어갈 수 있는 사이트들이 많다.
이유는 과도한 크롤링으로 인한 서버 과부화 + 해커들의 공격을 막기 위한 보안 목적이 있다.
2-3. HTTP Request 실행 결과
각자 결과들을 보면 쓸모없는 링크가 있다던지, HTML 문법이 있다던지 등등 필요없는 내용이 너무 많다.
이것을 그대로 AI Agent한테 다 줘도 알아서 잘 요약해준다.
근데 왜 이것을 바로 AI Agent한테 주지 않을까?
정답은, 내 돈…. 때문이다… .
우리는 token 사용량에 따라 요금을 지불을 할텐데 이렇게 많은 쓸모없는 녀석들까지 넣어버리면 사용하는 token은 어마무시하게 많아지고 그러면,,, 내 지갑은 텅장이 될 것이다,,,,, :(
그렇기에 AI Agent에 들어가기전에 쓸모없는 부분들을 제거를 하거나, 필요한 부분만 추출 해야한다 라는 생각이 들 것이다.
3. Code 노드 생성 및 Data 정제
이제 저 긴 HTML을 정제를 통해서 최대한 필요한 부분만 뽑아야한다.
우선 내가 필요한 부분은 ‘기사 제목’, ‘기사 내용’, ‘카테고리’ 를 추출하기로 생각했다.
스터디장님은 “Code”라는 node를 사용하셨는데 사실 나는 Java에서 추출하는 법을 몰랐기도하고 python을 사용할 줄 알지만 최대한 노코드로 쉽게 가져가려고했다. 누구나 조금이라도 쉽게 할 수 있으면 좋으니까,,,
AI에게 좀 더 다른 방법이 없는지 물어봤다.
이 방법이 노코드이긴하지만 HTML을 조금 아시거나 크롤링을 조금 하셨던 분들은 쉽게 이용할 수 있을 것 같았다.
사실 처음 하시는 분들도 코드를 짜는 것보다 조금만 공부해서 이 방법을 사용하시는 것을 추천합니다.
(Code in JavaScript를 사용해도 어차피 공부해야할 부분이다)
1) 은 저 상태로 냅두면 된다.
처음에는 “JSON Property”에 input에 있는 data를 넣었는데 오류가 났다.
| JSON Property = data라고 쓰면 | JSON Property = 드래그해서 {{$json.data}}가 들어가면 |
|---|---|
| -> 현재 item의 data라는 필드 이름을 보고 -> 그 안에 있는 HTML 전체 문자열을 가져와서 파싱 |
“JSON Property에 들어있는 문자열을 키 이름으로 생각하고, 그 키를 가진 필드를 찾겠다.” |
2) 여기서 입력할 값들 중 CSS_Selector 부분은 HTML을 좀만 볼 줄 알면 된다.
그리고 이건 사이트마다 다르기때문에 사이트마다 다르게 해줘야 한다.
우선 지금은 “매일경제”를 사이트를 가져오기에 기준을 매일경제로 잡고 진행한다.
- Key: 내가 이 데이터 즉 CSS_Selector 에서 가져오는 데이터를 어떤 이름으로 지정할 것인가?
- 제목을 가져올 거라면 title / 내용을 가져올 거라면 contents 등등 자신만의 방법
- CSS_Selector: 내가 해당 기사의 어느 특정 부분을 가져올 것인가?
- Return Value: 총 4가지가 있는데 우리는 HTML 문법빼고 Text만 사용할 것이므로 보통 text를 선택한다고 보면된다.
- HTML로 해도 되긴하는데 HTML로 하면 필요하지 않는 HTML 문법이 포함되어 우리의 token 사용량이 불필요하게 많아지기 때문에 text를 선택하는 것이 맞는 것 같다.
- 직접 HTML과 Text를 선택해서 해보시면 왜 이런말을 하는지 알 수 있다.
그럼 이제 값을 가져와보자.
제목만 가져오는 것만 첨부하고 나머지는 직접 해보시면서 깨달으면 좋을 것 같습니당
1) 을 하기 전에 F12를 클릭하여 우측에 이상한 영어들이 많이 나오게한다.
그 후, 1)을 누르고 왼쪽에 내가 제목을 가지고 오고싶다 하면 2) 제목 쪽(혹은 내가 원하는 쪽)에 마우스를 가져다 대고 저렇게 영역이 표시되게 한다.
그 후 클릭!
클릭을 하면 내가 선택한 영역 즉, 3)을 보면 내가 클릭한 부분의 HTML이 보인다.
저기서 class=”news_ttl” 이라고 되어있는데 이를 더블클릭해서 복사해온다.
복사한 것을 CSS_Selector에다가 “.news_ttl” 을 넣어주면된다.
이건 제목이기에 Key 값에다가는 title이라고 입력했습니다.
또한, Return Value에는 위에서 말했듯이 불필요한 token 사용량을 막기 위해 Text를 선택한다.
(TIP: class에 띄어쓰기가 있으면 그 부분은 ‘.’으로 채워주면 됨.
ex) class가 ‘news ttl’ 라면 n8n CSS_Selector에는 ‘.news.ttl’ 로 입력해야한다.)
제목, 내용, 카테고리를 모두 가져오고 실행을 하면 이미지와 같이 OUTPUT이 내가 설정한 Key 값별로 정리되어서 나온다.
스터디장님은 모든 카테고리를 가져오는 RSS를 사용해서 카테고리를 filter node를 사용해야했지만 나는 매일경제에서 부동산 카테고리의 RSS를 가져왔기에 다른 filter node는 필요없다.
4. AI Agent node 생성 및 프롬프트 입력
이건 전에도 했었고 이번 실습은 RSS 사용과 Telegram 연동이 주 기능이기에 하나의 AI Agent만 연결해서 이후 텔레그램 연동까지 해보겠다.
[기사] 내용을 요약해서 작성한다.
- 다른 사담은 필요없고 요약 내용만 정리한다.
- 이를 텔레그램에 올릴 것이다.
- [형식]에 맞춰서 작성한다.
---
[기사]
제목: {{ $json.title }}
내용: {{ $json.category }}
출처: {{ $('RSS Feed Trigger').item.json.link }}
---
[형식]
요약한 제목
요약 내용
출처:해당 링크
5-1. Telegram 토큰 및 id 값 발급 받기
1) https://telegram.me/BotFather 에 접속한다 (desktop으로 진행)
2) ‘/newbot’ 입력 -> bot 이름 입력 후 엔터 -> username 입력
(주의) username은 다른사람이 사용하지 않는 이름(유니크값) + bot으로 끝나야함
중간에 n8n_test_bot이라고 username을 만들었다가 이미 있다고 퇴짜 맞음,,, 그래서 n8n_sh_test_bot 이라고 이름을 지어줬다.
빨간색으로 가려진 부분에 API를 복사하여 보관한다.
3) n8n과 telegram을 연동하려면 Chat ID를 확인해야한다.
- 웹 주소창에 아래와 같이 입력하고 엔터를 누른다.
https://api.telegram.org/bot[발급받은 토큰값]/getUpdates
아직까지는 result 값에 아무것도 뜨지 않는다. 우선은 ok:true가 되면 성공
그 후, 아까 우리가 토큰을 발급받은 채팅창을 다시보면 링크가 있다.
이것이 우리 bot이 동작할 채팅창인 것 같다? (나중에 확인 해봐야지,,)
이것을 클릭하고 채팅창에 아무거나 입력해본 후에
다시 “https://api.telegram.org/bot[발급받은 토큰값]/getUpdates”를 들어가보면 머라머라 길게 뜨면 성공! 여기서 필요한건 id값이다.
5-2. Telegram과 n8n 연동하기
1) telegram - send a message node 만들기
2) Credential to connect with 설정하기 = 봇을 사용할 수 있는 권한 설정
- 토글바를 누른다 -> Create new credential 클릭 -> 발급받은 토큰 넣기 -> Save -> 성공했다라는 문구 뜨면 연결 성공
3) 발급받은 Chat ID입력 -> INPUT에서 AI Agent가 출력한 값을 Text에 드래그
4) 실행 결과 및 파일
[느낀점]
몬가 된다,, 그리고 실제로 결과가 나와서 1시간마다 telegram 알람이 오는걸 보면 캡쳐해서 올리겠다.
중간에 css_selector을 적는 부분이 있었는데 selenium과 beautifulsoup을 많이 사용했보니까 확실히 가져오고 적용하는 부분에서는 속도감 있게 진행을 할 수 있었다. 이런거 보면은 언젠간 공부한거 다 써먹는다,, 라는 말이 맞는것 같기도??
또한 이제 진짜로 자동화가 시작되는 기분이라 이것을 어떻게 활용해서 내 업무를 자동화 할 수 있을지 고민을 해봐야겠다고 느꼈다. threads나 오픈 카톡방에서 보면은 잘 활용하시는 분들 있는데 이번 공부를 통해서 이 분들이 노드를 어떻게 짯고 이용했는지 플로우를 대략적으로라도 파악할 수 있게 되었다!!
앞으로 남은 2주도 화이팅
[학습 정리 자료]
- 본문 링크 : 네이버 블로그 원본
- 하면서 났던 오류들 수정한 내용 - 지속 누적할 예정
댓글남기기